ReLU 활성화
분류 기초 · easy
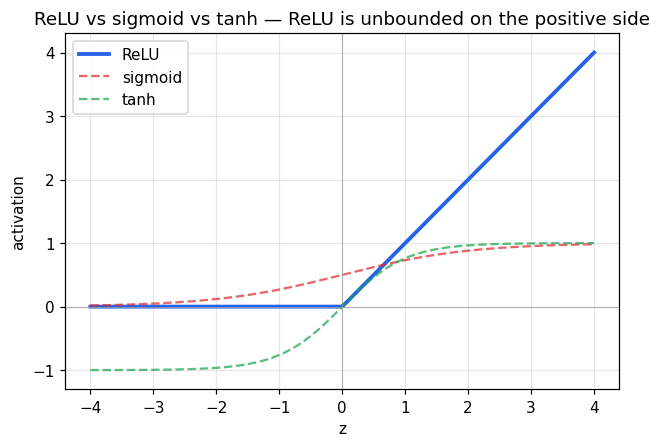
ReLU (Rectified Linear Unit)
현대 딥러닝의 기본 활성함수. 단순하지만 게임 체인저였어요:
왜 강력한가
시그모이드·tanh와 비교:
| 활성 | 포화 영역 | 미분 |
|---|---|---|
| sigmoid | 양끝에서 0에 가까움 → vanishing gradient | |
| tanh | 양끝에서 0에 가까움 | |
| ReLU | 음수에선 정확히 0 (dead neuron) 가능, 양수에선 미분 = 1 | 1 (양수) / 0 (음수) |
ReLU는 양수 영역에서 그래디언트가 죽지 않아서 깊은 망의 학습 을 가능하게 만들었습니다. 단점: 음수 입력이 계속되면 뉴런이 "죽을" 수 있음 → Leaky ReLU, ELU 등 변형이 나옴.
과제
함수 relu(z) 를 완성하세요.
- 스칼라 또는 NumPy 배열 입력.
np.maximum(0, z)가 가장 깔끔.- 반환: 같은 shape.
테스트 케이스
| # | 이름 | 입력 | 기대 |
|---|---|---|---|
| 1 | 양수 그대로 | 5.0 | 5.0 |
| 2 | 음수는 0 | -3.5 | 0.0 |
| 3 | 0은 0 | 0 | 0 |
| 4 | 벡터 입력 | [-1, 0, 1, 2] | [0, 0, 1, 2] |
| 5 | 음수 배열 전체 0 | [-2, -1, -0.1] | [0, 0, 0] |
Loading...
코드를 작성하고 Run 을 눌러보세요.