결정계수 (R²)
평가 지표 · easy
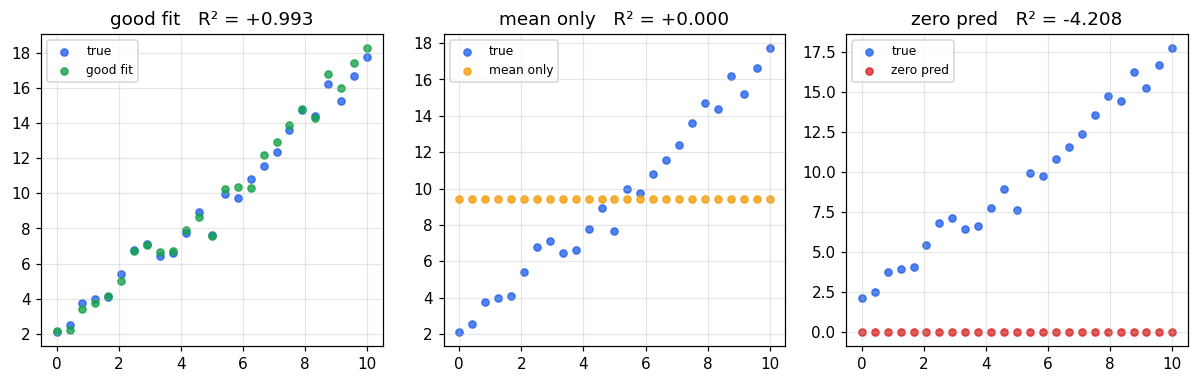
결정계수 (R²)
회귀 모델의 표준 평가 지표. "평균만 예측하는 bar 모델" 에 비해 얼마나 낫냐 를 묻습니다:
분자는 잔차 제곱합 (SSR), 분모는 총 변동 (SST).
해석
| R² | 의미 |
|---|---|
1.0 | 완벽한 예측 |
0.0 | 평균 예측과 동일한 성능 (쓸모없음) |
| 음수 | 평균 예측보다 더 나쁨 — 모델 망가진 상태 |
가까워질수록 좋지만, 과적합으로 R²만 높을 수 있어 다른 지표(MAE, CV 등)와 함께 봐야 합니다.
과제
함수 r2_score(y_pred, y_true) 를 완성하세요.
- 반환: Python
float. - 힌트: SSR =
((y_true - y_pred)**2).sum(), SST =((y_true - y_true.mean())**2).sum(). - SST == 0 (상수 타깃) 경우 방어해도 좋음 (
0.0반환).
테스트 케이스
| # | 이름 | y_pred | y_true | 기대 |
|---|---|---|---|---|
| 1 | 완벽 | [1, 2, 3] | [1, 2, 3] | 1.0 |
| 2 | 평균 예측 | [2, 2, 2] | [1, 2, 3] | 0.0 |
| 3 | 일반 | [1, 2.5, 2.5] | [1, 2, 4] | 0.73~0.75 |
| 4 | 매우 나쁨 | [0, 0, 0] | [1, 2, 3] | 음수 |
| 5 | sklearn 일치 | random 데이터 | sklearn.metrics.r2_score 와 |
Loading...
코드를 작성하고 Run 을 눌러보세요.