정확도 (Accuracy)
평가 지표 · easy
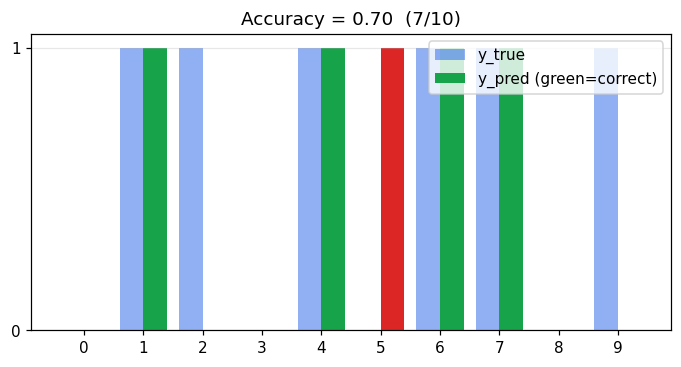
정확도 (Accuracy)
가장 기본적인 분류 성능 지표 — 맞춘 비율.
범위 . 단순하지만 클래스 불균형에서는 오해를 부릅니다 (예: 양성 1%인 데이터에서 "모두 음성" 예측이 99% 정확도 — 전혀 쓸모없음).
과제
함수 accuracy(y_pred, y_true) 를 완성하세요.
- 입력: 정수 또는 bool 형 1D 배열 두 개 (같은 길이).
- 반환: Python
float,0.0 ~ 1.0. ==와np.mean이면 한 줄.
테스트 케이스
| # | 이름 | y_pred | y_true | 기대 |
|---|---|---|---|---|
| 1 | 전부 맞음 | [0, 1, 1, 0] | [0, 1, 1, 0] | 1.0 |
| 2 | 전부 틀림 | [1, 0, 0, 1] | [0, 1, 1, 0] | 0.0 |
| 3 | 반반 | [0, 1, 1, 0] | [0, 0, 1, 1] | 0.5 |
| 4 | 다중 클래스 | [0, 1, 2, 1, 0] | [0, 1, 0, 1, 0] | 0.8 |
| 5 | 빈 배열 방어 | 길이 0 | 길이 0 | 예외 없이 처리 |
Loading...
코드를 작성하고 Run 을 눌러보세요.